
NVIDIA H200 Tensor Core GPU を搭載した EC2 インスタンスが東京リージョンに初登場 P5en インスタンス一般提供開始されました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
東京リージョンには未提供だった P5e のネットワーク強化版の P5en が東京リージョンを含め一部リージョンで一般提供開始されました。CPU と GPU 間のデータ転送速度の改善がされた NVIDIA H200 Tensor Core GPU を 8 基搭載したインスタンスタイプです。
3行まとめ
- H200 Tensor Core GPU を 8 基積んだ P5e のネットワーク強化版がリリース
- CPU と GPU 間の帯域幅が最大 4 倍になり、パフォーマンス向上
- H200 Tensor Core GPU を搭載したインスタンスタイプは東京リージョンでは初めて
インスタンスタイプの説明
Amazon EC2インスタンスタイプの選び方ガイドから抜粋して、インスタンスタイプの説明をします。
頭文字のインスタンスファミリーを示しています。Pは大規模の GPU を搭載した EC2 インスタンスです。
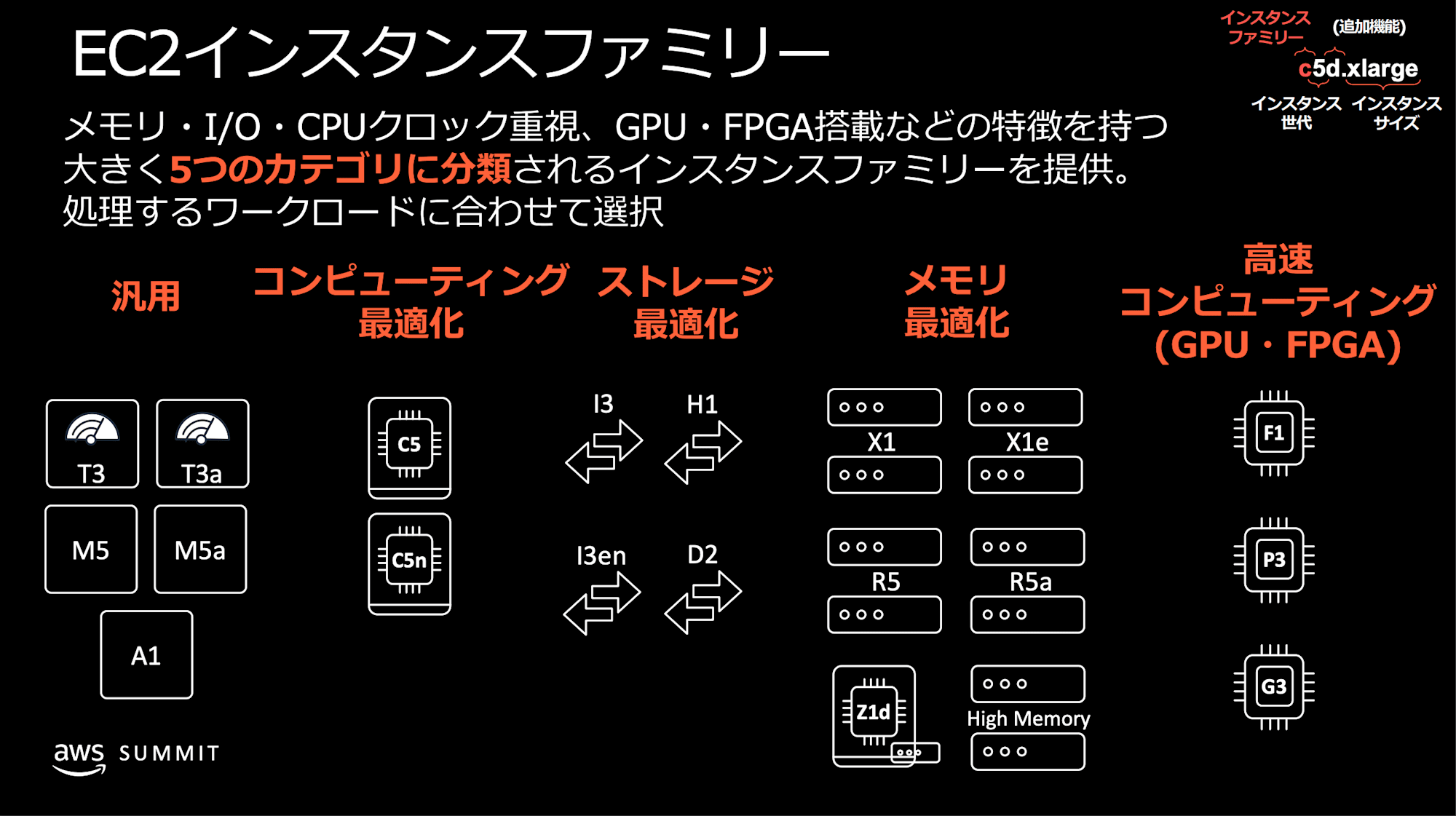
eとnは追加機能を示しています。eは通常とは違うスペックを意味します。P5からP5eがリリースされたタイミングで、NVIDIA H100 Tensor Core GPU から、H200 Tensor Core GPU へ変更されたことを指しています。今回のアップデートはnが付与されて、従来のP5eのネットワークが強化されたインスタンスとなりました。
スペック表
P5eから引き続き H200 Tensor Core GPU を 8 台搭載しています。

参考: New Amazon EC2 P5en instances with NVIDIA H200 Tensor Core GPUs and EFAv3 networking | AWS News Blog
価格
リリース時点では東京リージョンは約 2 割増しの単価です。単価が単価だけに海外リージョンの利用可能ならそれだけで 20%オフです。
| AWSリージョン | EC2インスタンスの時間単価 |
|---|---|
| 東京 | $106 |
| オハイオ | $84.8 |
| オレゴン | $84.8 |
東京リージョンの提供状況
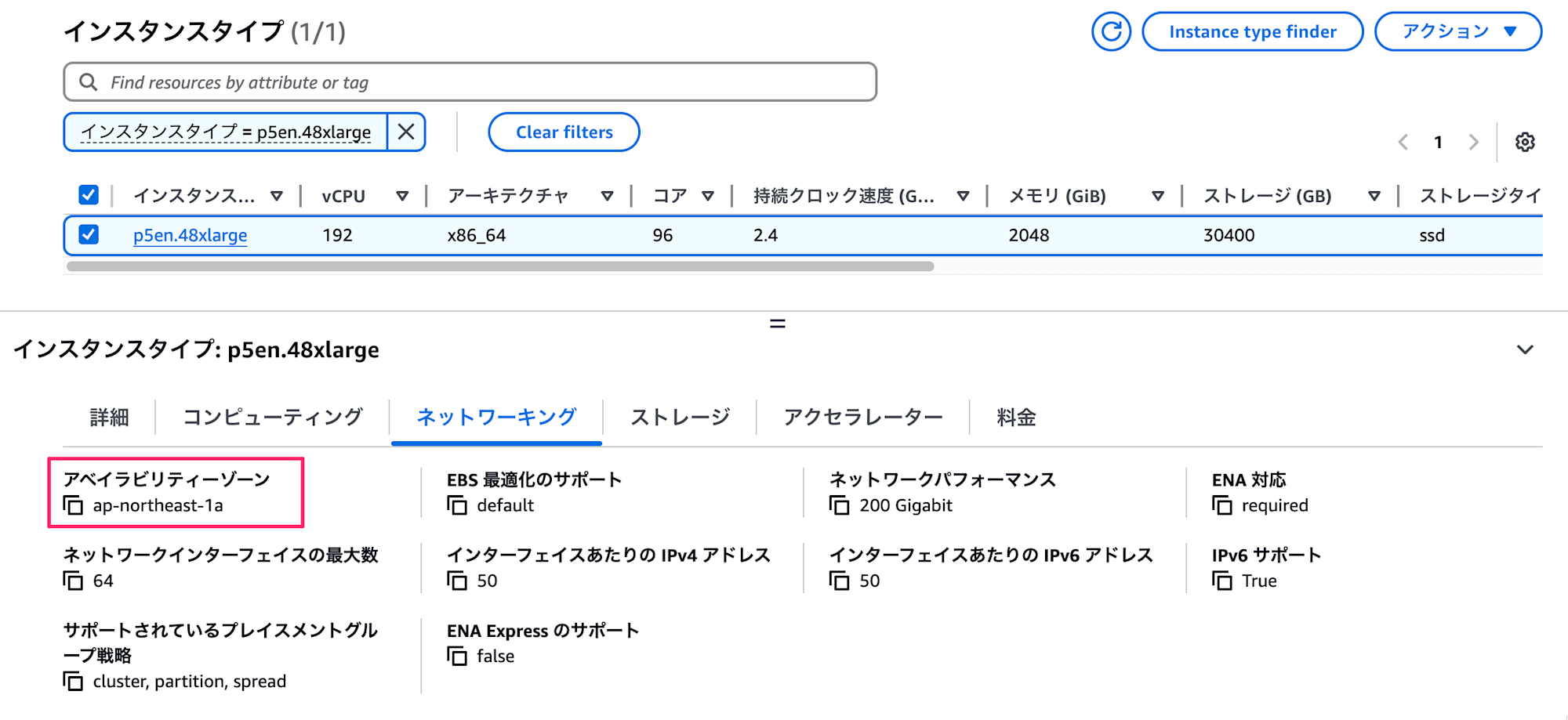
現在は 1 AZ のみの提供となっています。既存のP5eは東京リージョンには未提供です。P5は提供されていますが、H100 Tensor Core GPU なので、H200 Tensor Core GPU を積んだインスタンスは日本初登場です。日本国内にしかデータを置けない事情がある方には朗報ではないでしょうか。
ネットワークが強化された背景
大規模なデータセットや、頻度の高いデータの交換を必要とするワークロードの場合は、CPU と GPU 間の通信に時間がかかることもあります。今回のP5enは従来のP5eと比較して、CPU と GPU 間の帯域幅最大 4 倍となりました。
恩恵を受けるユースケース
- 大規模言語モデル(LLM)を始めとするモデルのトレーニング
- ファインチューニング
- 推論実行時のレイテンシー改善
- シュミレーション、創薬、天気予報などのメモリ集約型の HPC ワークロード
AWS ParallelCluster で AWS Trainium チップと利用した LLM のトレーニングした記事があります。同様の手法でP5en.48xlargeインスタンスを利用してトレーニングができるわけです。
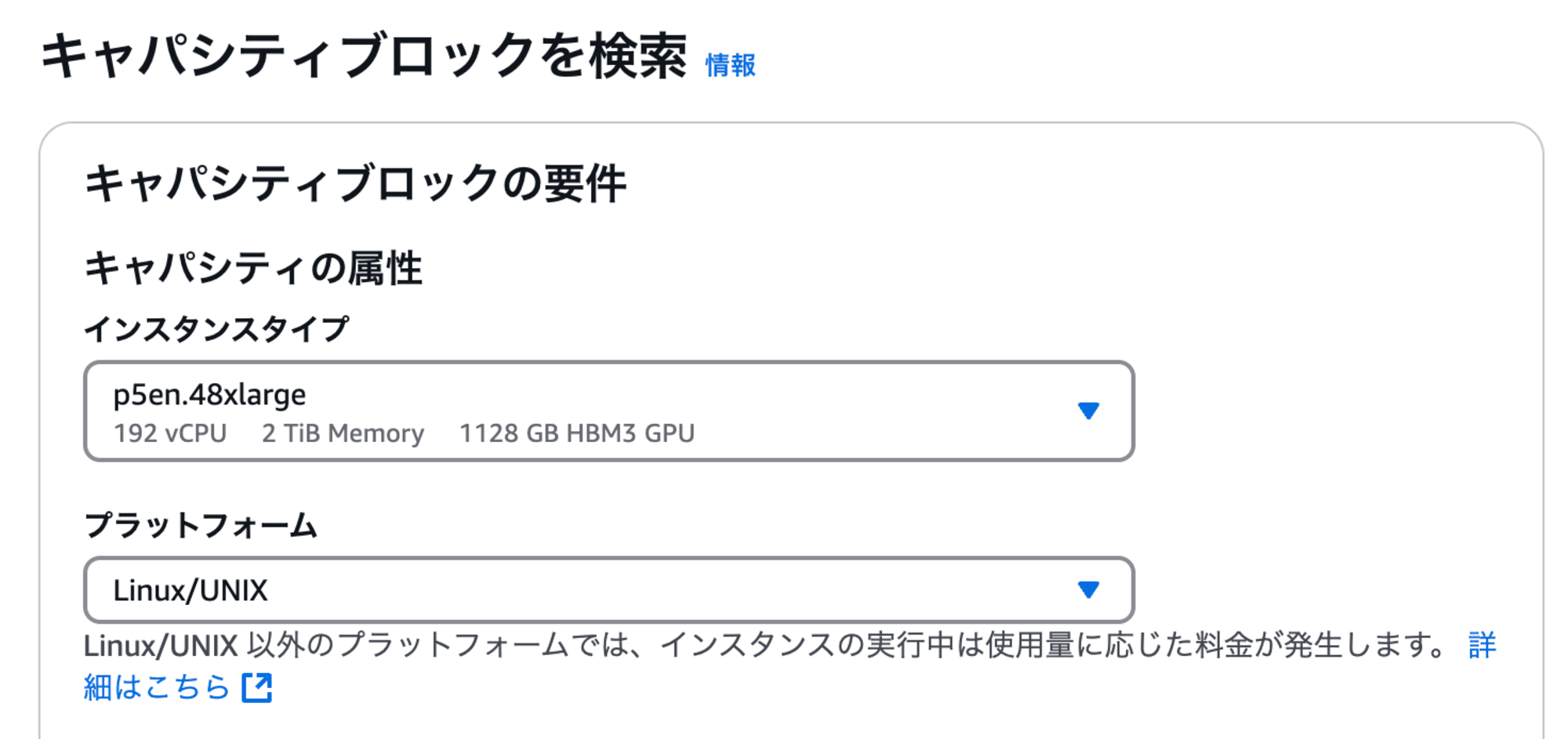
EC2 Capacity Blocks for ML に対応
昨今の GPU 需要は非常に高く使いたいときに GPU インスタンスを使えるかというとあやうくなってきました。そこで、事前に GPU インスタンスの起動枠を予約できるサービス EC2 Capacity Blocks for ML があります。P5enは予約対象になっています。現時点ですと東京リージョンだと選択対象にP5enの表示はありませんでした。
まとめ
H200 Tensor Core CPU を 8 基積んだ P5e のネットワーク強化版がリリースされました。また、H200 Tensor Core GPU を搭載したインスタンスとしては日本初登場です。
おわりに
大規模言語モデルのトレーニングなど GPU インスタンスの需要が高まる昨今、それに対応するアップデートでした。









